【Python】爬蟲 workshop
在這資訊爆炸的時代,我們可以使用在網路上的大量資訊,但為了找到特定資料,你是否經歷逐筆抓取及整理資料的痛苦?別擔心!網路爬蟲可以解決逐筆複製貼上的痛點,不僅提升效率還節省時間,看完這篇爬蟲介紹文一起建立基礎吧!

本篇文章 key takeaway
- 了解網頁基本架構
- 爬取 PTT 資料並用 cookie 越過確認頁面
- 抓取維基百科中特定關鍵字的網頁內文
- 爬取金融網站資料並繪製成圖表
目錄
- 爬蟲基本介紹
- 網頁架構概覽
- 爬蟲基本技巧
- 實作範例
講者介紹
吳証恩,臺大資料分析與決策社第二屆課程長,目前正在攻讀台大統計碩士,並在商研所所長的實驗室擔任 RA。
爬蟲基本介紹
資料是資料分析之根本,學習網路爬蟲便能快速的獲取網路上存放的海量資料,增加資料分析的效率。
爬蟲,又稱網路蜘蛛(spider),簡而言之就是利用程式語言──我們這堂課用業界最常用的 Python,去模擬使用者的行為,將複製貼上這種繁瑣的行為自動化,讓資料獲取更為方便快速。

網頁架構概覽
網頁架構三兄弟

建構出眼前網頁的元素主要有三個:HTML、CSS、JS。
HTML 負責建立網頁的主結構,是網頁內容的描述語言,後續會再詳細介紹;CSS 則是網頁外觀型態的描述語言,負責美化網頁;JS 是直譯式程式語言,負責網頁與用戶的互動。
網路世界的溝通語言──HTTP
上面介紹的 HTML 是網頁內容的描述語法,而接下來要介紹的 HTTP 則是負責建構網頁連結路徑的語法,它用來讓瀏覽器從伺服器取得內容供網頁呈現使用。
當我們開啟新網頁時,瀏覽器會由多個程序聯合運作來和伺服器溝通以完成任務,最後才能呈現出我們眼前的瀏覽器畫面。

其中,瀏覽器與伺服器之間的溝通語言就是 HTTP,因此,進行網路爬蟲前要先認得 HTTP的語法。
HTTP 的全名是超文本傳輸協定,其中有八種標準化方法(standardized method),包含GET、HEAD、POST、PUT、DELETE、TRACE、OPTIONS及CONNECT,他們各自有不同的功能。
正常來說,所有伺服器都必須支援 GET 與 HEAD 方法。 GET 得以展示指定資源的表示狀態(representation),而 HEAD 方法雖請求與 GET 方法相同之回應,但伺服器只會傳輸狀態行以及表頭部分,缺乏回應主體,所以我們主要是以 GET 方法來進行網路爬蟲。

查看網頁原始碼
- Chrome
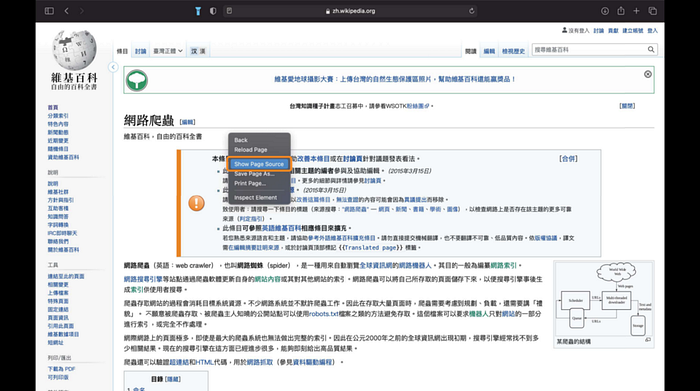
按右鍵的「檢查」(inspect),網頁原始碼會出現在畫面右邊。
快捷鍵:Ctrl + U (IOS系統)

2. Safari
點選 Safari 中的「偏好設定」(Preferences),進入「進階」(Advanced)視窗後,勾選視窗最下方的「在選單列中顯示開發選單」 (Show Develop menu in menu bar)。
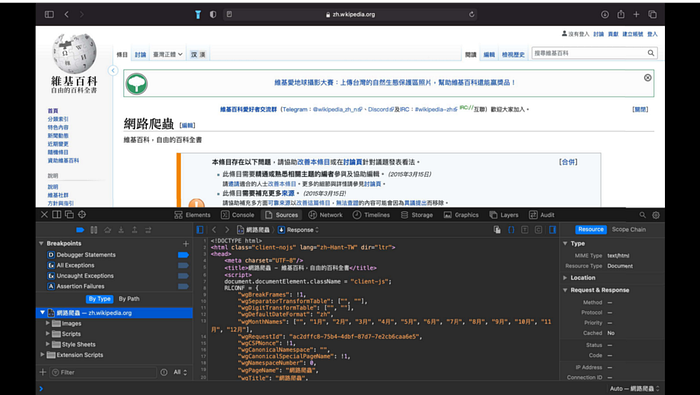
按右鍵的「顯示網頁原始碼」(show page source),網頁原始碼會出現在畫面下半部。
快捷鍵:option + command + u (IOS系統)

爬蟲基本技巧
基本技巧三步驟

beautifulsoup 常用功能
– find()
– .text
– find_all()
– get()1. find()
只搜尋第一個符合條件的HTML節點,傳入要搜尋的標籤名稱。
可加入參數 class_ 來搜尋符合的CSS屬性。
2. find_all()
搜尋網頁中所有符合條件的HTML節點,傳入要搜尋的HTML標籤名稱。
可加入參數 class_ 來搜尋符合的CSS屬性。
3. get()
取得指定標籤內的指定屬性。
正規表達式 Regular Expression
正規表達式是用來匹配字串中字元組合的模式,可以利用它來找出一段文字中的 email、電話號碼、身分證字號等。所以進行網路爬蟲的時候,可以利用正規表達式來找尋特定字詞,達成資料篩選的效果,以下介紹常見用法的 code。
取代掉指定的字元
取代指定的次數
取代幾組特定的組合
以附近出現的字搜尋 (look around):(?=)、(?!)、(?<=)、(?<!)
只搜尋頭尾 (anchor): ^、$
實作範例
1–1. 爬 PTT — Food 版文章資訊
目標:
印出Food板(https://www.ptt.cc/bbs/Food/index.html)中最新文章的「作者」「標題」「時間」
步驟:
GET網頁原址碼 ( requests.get( ) )- 找到 「作者」、「標題」、「時間」的位置(Inspect element)
- 用 sour.find( ) 或 soup.find_all( ) 搜尋
- 用 for 迴圈印出所有的「作者」、「標題」、「時間」
輸出結果範例:
作者:vicky11016
標題:[食記] 台北信義。牛翻天牛肉麵
時間:5/13作者:kamgx58
標題:[食記] 高雄 靠杯咖啡 美術館青海路 不限時有插座
時間:5/13作者:shangyikuo
標題:[食記] 花蓮市區 雨林Scone&Coffee
時間:5/13作者:QtGirl
標題:[食記] 台北 京都勝牛:來自日本的炸牛排名店
時間:5/13
1–2. 爬 PTT —真實用戶登入授權
目標:
可以自動認證真實用戶登入授權,讓網路爬蟲擷取 「18歲以上」才能瀏覽的版(e.g. 八卦)之資料。
步驟:
解決辦法就是在 code 中加入 cookie 一同執行,讓瀏覽器知道我們已經勾選過「18歲以上」,就可以成功越過真實用戶登入授權囉!以下說明如何查閱 cookie 狀態,並利用觀察結果寫出 cookie 的 code。
1. 開啟無痕模式,連到PPT八卦版網頁
2. 按右鍵中的「檢查」,得到網頁原始碼
3. 點選視窗上方工具列中的 "Application"
4. 點選視窗左邊的 Storage 下的 Cookies類別,點選 "https://www.ppt.cc"
5. 回到網頁頁面,點選「我同意,我已年買十八歲 進入」按鈕
6. 可以觀察到 cookies 欄會出現「over18」
2. Wikipedia — 爬關鍵字文章
目標:
1. 從 Wikipedia 中,鎖定一個搜尋關鍵字,擷取該關鍵字詞的內文。
2. 獲取該頁面中所有 Wikipedia 的超連結。
步驟:
- 取得網頁原始碼
- 印出所有文章內容
- 印出所有 wiki 超連結
I. 爬取當前關鍵字內容,並存入檔案。
II. 萃取出當前關鍵字所引用的外部連結,當作新的查詢關鍵字。
III. 把II. 擷取到的關鍵字當作新的關鍵字,回到第 I. 步,爬取新的關鍵字內容。
3. 台灣銀行牌告匯率
目標:
利用爬蟲擷取美金歷史匯率資料,並畫成歷史匯率軌跡圖
步驟:
參考網站
- 好用的Regex語法網站:Regular Expression 101
- BeautifulSoup實用技巧
